The U.S. Local Search Ecosystem
Get a better understanding of how data providers, search engines, and directories exchange and access business data. The Local Search Ecosystem (LSE) is your resource to identify the most important sources for correct and accurate business information online.
This resource is dynamic. Hover over each segment to see the specific relationships and how information flows. Click segments to lock them.
The Local Search Ecosystem is the brainchild of David Mihm and was first developed in 2009. The LSE shows how business information is distributed online, who the primary data providers are, how search engines use the data, and how it flows.
Whitespark and David Mihm teamed up to map the Local Search Ecosystem for the USA and provide a clearer picture of how information flows in today’s search environment.
Data Sources
In the United States there are four Primary Data Aggregators: Infogroup, Neustar/Localeze, Factual, and Foursquare (*previously Acxiom, however, with the business directory closing at the end of 2019, we believe Foursquare is in a position to take it’s place). These companies collect local business information and have massive data-sets in which they validate and vet the information provided. Search Engines like Google, Bing, and Apple license the primary aggregators data.
Other Key Sites like Facebook, Yelp, Yellowpages, CityGrid, and Dun & Bradstreet, also play a role in sending data feeds to Search Engines.
Search Engines manage their own databases, however, they utilize the information provided to them through the above mentioned sources. If the business data on any of these primary sources is incorrect it can override the information that is already available in the Search Engine’s database, this can lead to either new listings being created or changing existing listing data. Bad NAP data can negatively impact your ability to rank in Google and Bing.
There are many Geo and Vertical Directories that are valuable citation sources that can drive traffic to your website and ultimately bring in more business. These directories also access the information from the various primary services and display the data on their sites. Which further increases the importance of having correct business information (Name, Address, and Phone Number) on all of these sites.
The LSE By Data Source to Display Platform
Interactive images are rad, but sometimes it’s also nice to see data in text format. Below is the flow of data from the source to display platform. Filter the data by Source, Type, Display Platform, or Relationship to see how the data flows.
| Data Source | Source Type | Display Platform | Relationship |
|---|---|---|---|
| Factual | Data Aggregator | Unconfirmed | |
| Factual | Data Aggregator | LocalStack | Confirmed |
| Factual | Data Aggregator | Apple | Unconfirmed |
| Factual | Data Aggregator | Manta | Confirmed |
| Factual | Data Aggregator | Bing | Unconfirmed |
| Factual | Data Aggregator | CitySearch | Confirmed |
| Factual | Data Aggregator | ShowMeLocal | Confirmed |
| Factual | Data Aggregator | YellowBot | Confirmed |
| Factual | Data Aggregator | TripAdvisor | Unconfirmed |
| Factual | Data Aggregator | Yelp | Unconfirmed |
| Infogroup | Data Aggregator | YellowPages | Confirmed |
| Infogroup | Data Aggregator | BrownBook | Unconfirmed |
| Infogroup | Data Aggregator | Superpages | Confirmed |
| Infogroup | Data Aggregator | Merchant Circle | Likely |
| Infogroup | Data Aggregator | LocalStack | Confirmed |
| Infogroup | Data Aggregator | Ziplocal | Likely |
| Infogroup | Data Aggregator | Insiderpages | Confirmed |
| Infogroup | Data Aggregator | DexKnows | Confirmed |
| Infogroup | Data Aggregator | Manta | Confirmed |
| Infogroup | Data Aggregator | Likely | |
| Infogroup | Data Aggregator | Bing | Confirmed |
| Infogroup | Data Aggregator | Citysearch | Confirmed |
| Infogroup | Data Aggregator | mapquest | Confirmed |
| Infogroup | Data Aggregator | Yellowbook | Confirmed |
| Infogroup | Data Aggregator | Whitepages | Confirmed |
| Infogroup | Data Aggregator | Showmelocal | Likely |
| Infogroup | Data Aggregator | Yahoo! Local | Likely |
| Infogroup | Data Aggregator | Yellowbot | Confirmed |
| Infogroup | Data Aggregator | CityGrid Media | Confirmed |
| Acxiom | Data Aggregator | HotFrog | Likely |
| Acxiom | Data Aggregator | Magic Yellow | Likely |
| Acxiom | Data Aggregator | BrownBook | Unconfirmed |
| Acxiom | Data Aggregator | Superpages | Confirmed |
| Acxiom | Data Aggregator | B2B Yellowpages | Confirmed |
| Acxiom | Data Aggregator | MyWebYellow | Likely |
| Acxiom | Data Aggregator | Apple | Unconfirmed |
| Acxiom | Data Aggregator | Likely | |
| Acxiom | Data Aggregator | Yellowbook | Likely |
| Acxiom | Data Aggregator | Local.com | Confirmed |
| Acxiom | Data Aggregator | eLocal | Likely |
| Acxiom | Data Aggregator | Mylocally | Unconfirmed |
| Acxiom | Data Aggregator | Chamber of Commerce | Likely |
| Acxiom | Data Aggregator | YellowBot | Confirmed |
| Acxiom | Data Aggregator | Yelp | Likely |
| Acxiom | Data Aggregator | Neustar Localeze | Unconfirmed |
| Neustar Localeze | Data Aggregator | Likely | |
| Neustar Localeze | Data Aggregator | YP | Confirmed |
| Neustar Localeze | Data Aggregator | EZlocal | Confirmed |
| Neustar Localeze | Data Aggregator | HotFrog | Likely |
| Neustar Localeze | Data Aggregator | MagicYellow | Likely |
| Neustar Localeze | Data Aggregator | Merchant Circle | Likely |
| Neustar Localeze | Data Aggregator | LocalStack | Confirmed |
| Neustar Localeze | Data Aggregator | B2B YellowPages | Confirmed |
| Neustar Localeze | Data Aggregators | ZipLocal | Confirmed |
| Neustar Localeze | Data Aggregator | Apple | Confirmed |
| Neustar Localeze | Data Aggregator | Likely | |
| Neustar Localeze | Data Aggregator | Bing | Confirmed |
| Neustar Localeze | Data Aggregator | HERE PrimePlaces | Likely |
| Neustar Localeze | Data Aggregator | mapquest | Likely |
| Neustar Localeze | Data Aggregator | Yellowbook | Likely |
| Neustar Localeze | Data Aggregator | YaSabe | Confirmed |
| Neustar Localeze | Data Aggregator | Yahoo! Local | Confirmed |
| Neustar Localeze | Data Aggregator | YellowBot | Likely |
| Neustar Localeze | Data Aggregator | TripAdvisor | Unconfirmed |
| YP | Key Site | Yelp | Unconfirmed |
| YP | Key Site | Yahoo! Local | Unconfirmed |
| YP | Key Site | mapquest | Unconfirmed |
| Dun & Bradstreet | Key Site | Manta | Confirmed |
| Yelp | Key Site | YP | Unconfirmed |
| Yelp | Key Site | Apple | Unconfirmed |
| Yelp | Key Site | Bing | Unconfirmed |
| Yelp | Key Site | mapquest | Unconfirmed |
| Yelp | Key Site | Yahoo! Local | Unconfirmed |
| Foursquare | Key Site | Apple | Unconfirmed |
| Foursquare | Key Site | Bing | Unconfirmed |
| CityGrid Media | Key Site | EZlocal | Unconfirmed |
| CityGrid Media | Key Site | InsiderPages | Unconfirmed |
| CityGrid Media | Key Site | Unconfirmed | |
| CityGrid Media | Key Site | Bing | Unconfirmed |
| CityGrid Media | Key Site | CitySearch | Unconfirmed |
| CityGrid Media | Key Site | mapquest | Unconfirmed |
Perfect & Expand Your Listings in the
Local Search Ecosystem
Our Local Listings Service can help you optimize your citations on the most important sites, fix inconsistencies, remove duplicates, and improve your local visibility.
Overview of Study
There have been quite a few changes to the LSE, from the data collection process to the new design and relationship classifications. Scroll down if you want an in-depth explanation of why these data sources have made the cut; you’ll get an overview of the history of this resource, implemented changes, and important observations made during the study.
Resources Used
- Distribution lists from aggregators
- Published attribution lists
- Whitespark’s Data Aggregators Study.
- Listings Service Reports generated in-house.
- Direct contact with the Top 50 Most Important Citation Sites.
Relationship Classifications
- Confirmed – through empirical studies, data aggregator lists, or from business directories.
- Likely – not tested, but reported on attribution pages or directly from the sites we contacted.
- Unconfirmed – these relationships are reported by data aggregator’s, but we could not confirm them in our empirical study.

New Design
We updated the design to reflect an eco-wheel that summarizes the data sources, relationship connections, and how information is pushed and pulled throughout the local search environment. The placement of Google is a very noticeable change, as it is not central to the image. We made this change because Google is a receiver of business information, rather than a provider, so in this sense its role is similar to that of any other business directory. A huge thank you to our amazing design team, Avenir Creative, for being so awesome to work with on this.
Definitions
Primary Data Aggregator
These are businesses whose business model consists of collecting and regularly updating and enriching business data, and then selling it to other companies, including business directories. They have the most influence in the ecosystem.
Core Search
Engines
The core Search Engines are Google, Bing, and Apple Maps. They are the most important display platforms that receive information from a multitude of different sources.
Other Key
Sites
These are sites that serve either as actual data providers of lesser significance (Dun & Bradstreet, Foursquare, CityGrid), or as important display platforms (Facebook), or in some cases both (Yellowpages, Yelp).
Geo & Vertical Directories
These are all other important business directories in the ecosystem that either receive, or (much more rarely) provide data from and/or to other sites.
Understanding the Local Search Ecosystem
Foreword
“When I developed the first Local Search Ecosystem graphic, I had little idea how widely shared and used it would become. We all know how quickly the local search space changes and the latest now-three-year-old graphic was woefully out of date. But as Tidings has become a full-time job (and a half!), I no longer have the bandwidth for search-focused projects, including the research of the latest data relationships or production of the graphic itself.
Darren offered Whitespark’s assistance in producing and maintaining an updated version, and since Nyagoslav and I had already partnered on the German version several years ago, it was a no-brainer to partner again once more. Darren pre-released the latest version to great acclaim at MozCon Local earlier this year, and I’m excited to see not only the dynamic version of the graphic come to fruition this year, but future enhancements and improvements from the Whitespark team.”
–David Mihm
A Brief History of the Local Search Ecosystem
When it comes to local SEO, there is hardly a more popular resource than David Mihm’s Local Search Ecosystem (LSE) infographic.
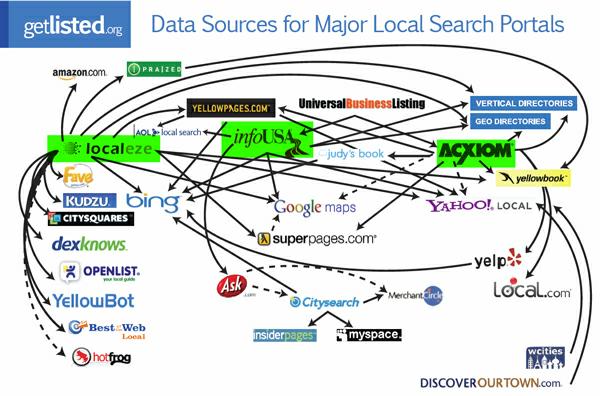
First published in 2009, the LSE attempted to explain visually the complexity of local data relationships, and why incorrect data so often found its way to the front page of Google or Bing. At that time very few people were aware of the fact that claiming and updating your Google local listing didn’t automatically mean that your business data would forever be displayed accurately on Google Maps, and even fewer knew how to make sure the information did stay correct. The LSE brought this unique local search issue to the SEO community’s attention, and eventually helped both agencies and businesses improve their local SEO processes.
2009 LSE:
Before diving deeper, a couple of terms need to be introduced in order for the ecosystem to be understood properly:
Data Aggregators
These are businesses whose business model consists of collecting and regularly updating and enriching business data, and then selling it to other companies, including business directories.
Business Data Feeds
When data aggregators collect business data, they compile it in a structured manner so that business directories (and other companies) can use it more easily, thus “feeding” them the business data.
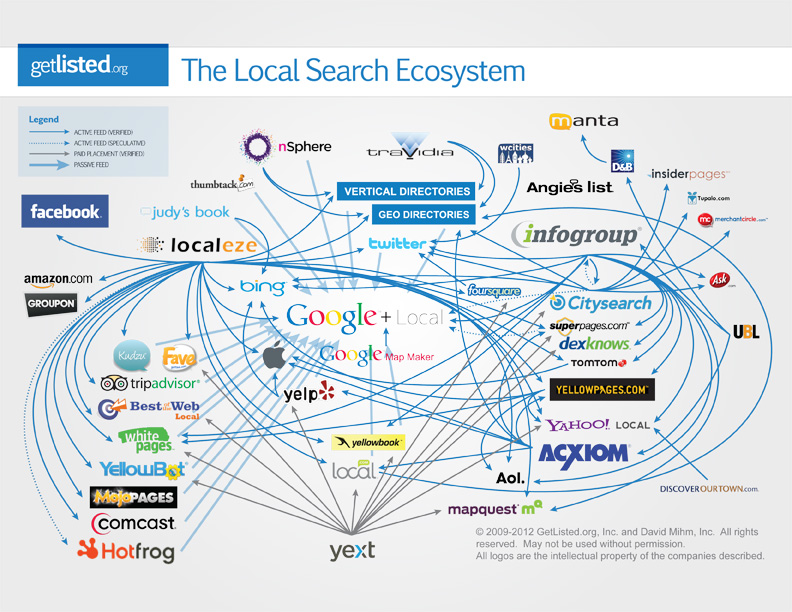
One challenge with the local search ecosystem is that it goes through frequent changes. New players come in, business directories stop operating, and the significance of the different data sources shift. This prompted David to produce two updated versions of the infographic – in 2012 and in 2014.
The most significant change in the 2012 version of the infographic was the introduction of Yext, although David himself concurred that it was questionable if Yext fit the purposes of the infographic. Other important important trends noted by David at the time were:
- The emergence of Google Map Maker as an important piece of the puzzle,
- The decreasing influence of Acxiom, and
- The increasing influence of Localeze.
2012 LSE:
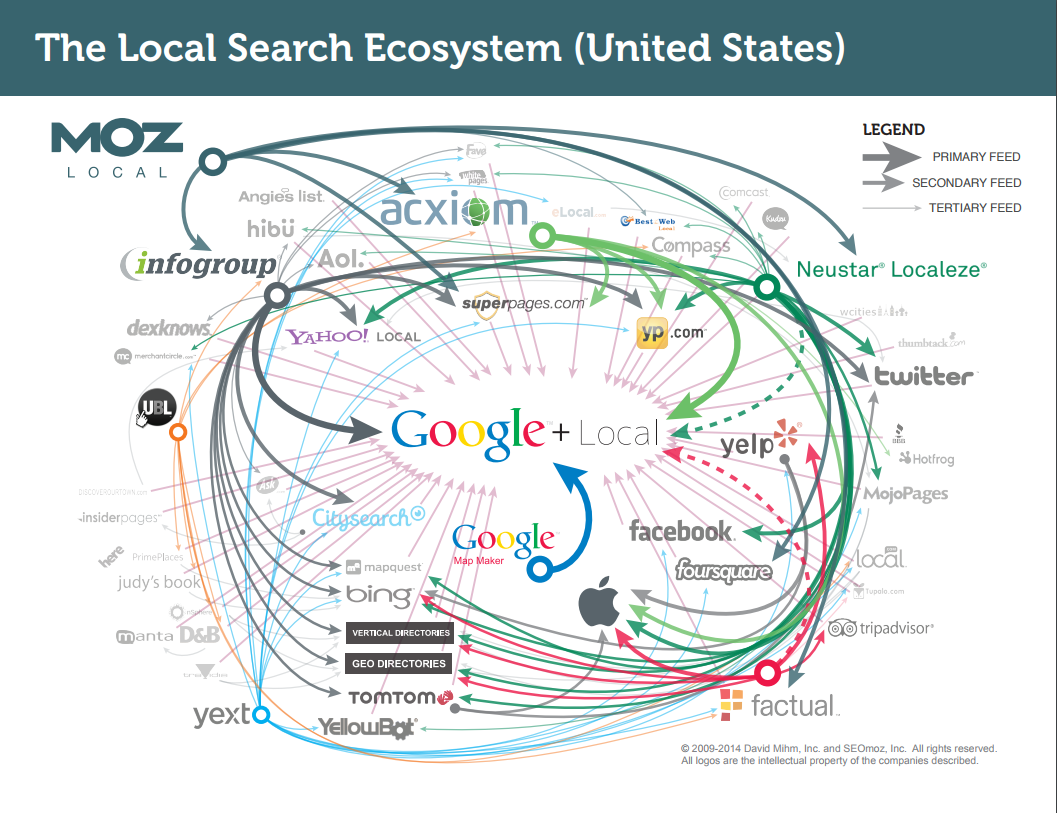
In the 2014 version, which was prepared when David served as the Director of Local Search Strategy at Moz, Moz Local was added as a new player, although similar concerns as the ones expressed in the 2012 version about Yext could be applied. David noted that Factual could by that time safely be considered one of the four major data aggregators.
2014 LSE:
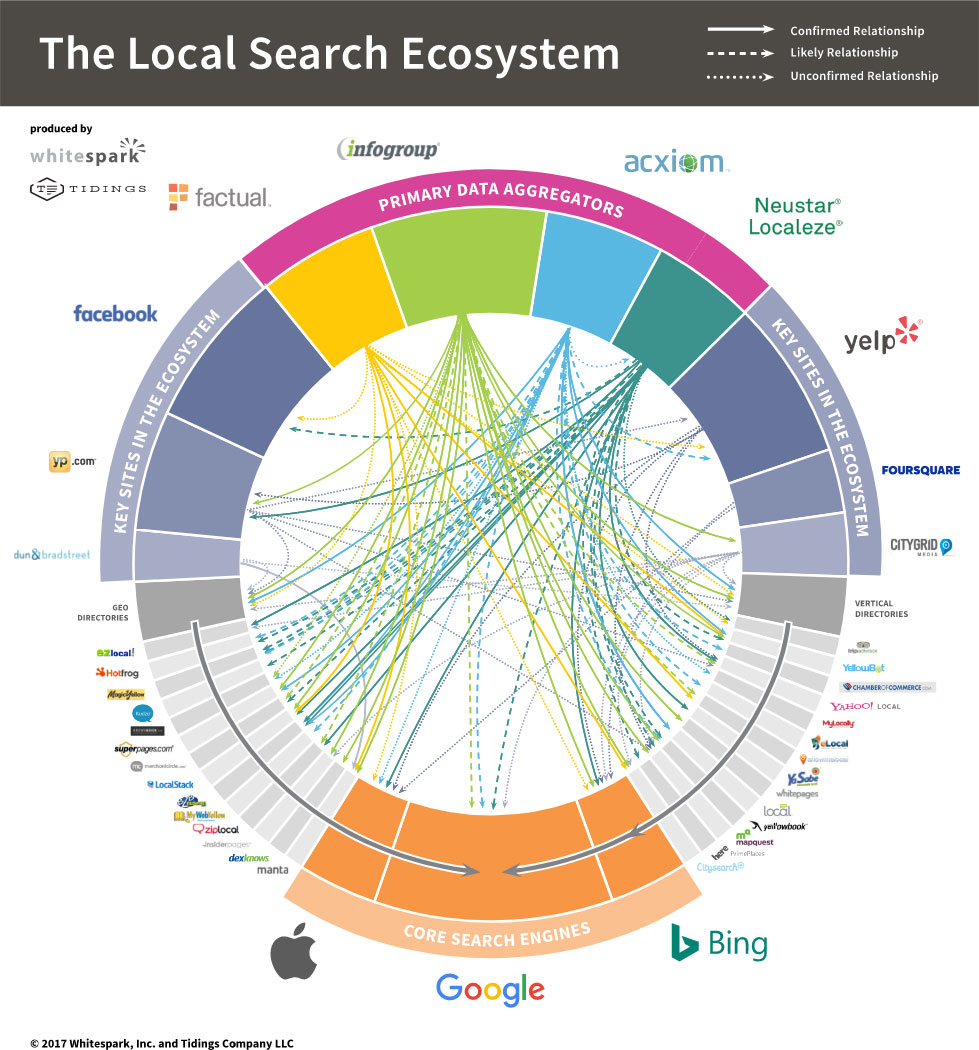
Understanding how the local search ecosystem works is of primary importance for the successful execution of a local SEO project; especially when tackling citation related work. A business listing that appears to be correct on the surface might become incorrect in a few weeks due to incoming third-party incorrect data, or data that already exists in the database of the site, but that hasn’t been surfaced yet. Sometimes the issue can run so deep and be so obscure that only a detailed citation audit (and subsequent citation clean-up) performed with thorough understanding of the local search ecosystem’s peculiarities might be able to remedy the situation. Thus, because of the frequently changing nature of the ecosystem and its importance, we asked David if he would be interested in collaborating to create an updated version.
2017 LSE:
Data Sourcing and Analysis Methodology
Up-to-date accurate data is the most important element of the Local Search Ecosystem, and as it turns out, the toughest to obtain. As a starting point we used the same groups of sources David used when working on the previous versions of the infographic:
A) Distribution lists we received directly from the 3 oldest and most important data aggregators (Acxiom, Infogroup, and Localeze);
B) Publicly available information, including data source attributions visible on business directory listings pages, “Terms of Service” pages, or other legal pages (for instance, check out the Attributions page of Apple Maps).
SuperPages Attributions:

MapQuest Attribution:

However, we realized that this information is insufficient and might not show the whole picture. Thus, we collected data relationships information in a few additional ways:
C) We performed a “Data Aggregators Study” in 2016, the results of which were first presented by Darren at Mozcon Local. At the beginning of the study we “seeded” data about imaginary businesses on each of the data aggregators. Then, using the Local Citation Finder and manual searches, we observed how many listings would be auto-generated and which sites these listings would be auto-generated on.
D) We analyzed 20 citation audit reports of our clients (“Citation Audits Study”). We checked listings that had been auto-generated (i.e. not created as a result of manual effort) and cross-referenced overlapping NAP data for listings on different data aggregators and business directories to determine which data aggregators and business directories frequently feature same business details.
E) We directly contacted each of the top 50 most important citation sites. We only received 3 replies, however, that contained useful information from the following 3 sites: EZLocal, Cylex, and MapQuest.
After compiling all this data we had the challenging task of reconciling it. In the process, we discovered that some of the data points were contradicting each other. Thus, we decided to introduce a new classification of relationships for this version of the LSE infographic:
Confirmed Relationships: relationships that were discovered during our empirical studies (Data Aggregators Study, Citation Audits Study, or both); in most cases these relationships were also confirmed either by the data aggregators’ distribution lists or by the business directories (or by both).
Likely Relationships: relationships that were not tested during our empirical studies, but were reported by the business directories (either in attributions pages on their sites or in their responses to our questions).
Unconfirmed Relationships: relationships that were reported by the data aggregators in their distribution lists, but were not confirmed by our empirical Data Aggregators Study.
It is important to note that our research suffers from certain limitations. For instance, our Citation Audits Study included analysis of citation audits that had been performed over a long period of time (approximately 1 year). As mentioned above, local search ecosystem relationships change frequently, so it is possible that such changes occurred from the time the first audit had been performed to the time the last audit was completed. As a result, the audit analysis data might be contradictory or incomplete.
Additionally, we tried to not over rely on self-reported data, data aggregators distribution lists, business directories attribution pages, and written answers by business directories, which all were important sources of information used when creating the final version of the infographic.
A critical problem that we faced when analyzing the data compiled during the Data Aggregators Study, was the issue of the origin of the data. For instance, if certain business data came to Site C directly from Site A (the arch-source), or if it first made its way from Site A to Site B, and only then from Site B to Site C (refer to the section below for a specific example of this).
Infographic Design and Data Relationships Explanation
When we first started discussing the idea of updating the LSE infographic, one of the main concerns we had was with the design of the previous versions. In earlier designs Google was prioritized and occupied very prominent central place in the infographic. However, while Google is the most important display platform for most businesses, its place in the local search ecosystem is not that central. Google is a receiver of business information, rather than a provider, so in this sense its role is similar to that of any other business directory. We discussed this issue with David and he suggested a rework of the design. After a number of failed redesign attempts, David came up with the brilliant “Eco-wheel” concept and we figured we could make it dynamic.
We have divided the players in the LSE into categories:
Primary Data Aggregators – these are the 4 data aggregators with most influence in the ecosystem (Infogroup, Acxiom, Localeze, Factual);
Core Search Engines – these are the most important display platforms that (predominantly) receive information from a number of different sources (Google, Bing, Apple Maps);
Key Sites – these are sites that serve either as actual data providers of lesser significance (Dun & Bradstreet, Foursquare, CityGrid), or as important display platforms (Facebook), or as both (Yellowpages, Yelp);
Other Sites – all other important business directories in the ecosystem that either receive, or (much more rarely) provide data from/to other sites.
Removal of Feed Sequence
Another feature that appeared in previous version of the LSE, but was dropped in the current version, was the different arrows that distinguished primary, secondary, and tertiary feeds. Some sites (such as the core search engines) receive data from a myriad of places. A good explicit example is the Apple Maps attributions page that features more than 50 sources of business listings data. Google and Bing obtain business data through both structured and unstructured citations (simple mentions of businesses in news articles, blog posts, forum discussions), which means that the number of potential data sources for these two search engines is practically infinite. Furthermore, it is very likely that all these search engines use “data freshness” as a major factor when deciding which data source will be displayed publicly. In some cases data from multiple sources might get merged together and certain bits of information from one source could be displayed together with bits of information from other sources.
All this makes it extremely difficult to determine which the primary, secondary, or tertiary data sources for a site at any given time are. It is much easier, however, to determine how likely it is that a site uses business data from certain source. That is why we introduced arrows that represent the likelihood of existence of a relationship instead.
Pay-to-Play Businesses Excluded
Finally, we decided to exclude agencies from this version of the LSE infographic. These include UBL, Yext, and Moz Local that were present in previous versions, as well as any other agencies that offer listing management solutions (including Whitespark). There are two reasons for this:
- First, we wanted to create an infographic that featured natural relationships between business data providers and data receivers, and the agency way of adding business data to the ecosystem is always “pay-to-play”.
- Second, including only some agencies that are able to add business data to the ecosystem is unfair, and there are tens, or even hundreds, of agencies that have special relationships with different data aggregators or business directories (for instance, see Factual’s list of Trusted Data Contributors).
Determining the Site Relationships
The different levels of Likelihood Of Relationships Between Sites In The Ecosystem (could be abbreviated as LORBSITE) have been mentioned a couple of times above, but some additional explanations are needed. We decided that when determining the LORBSITE we would assign different levels of trust to different information sources based on how likely it was that certain information was accurate and up-to-date. The sources were ordered in the following manner in terms of trustworthiness (starting from the most trustworthy):
- Relationship data discovered during Data Aggregators Study
- Relationship data discovered during Citation Audit Study
- Relationships reported by business directories answering our email questions
- Relationships mentioned in attribution pages (or other pages) on business directory sites
- Distribution data provided by data aggregators
If relationship data between two (or more) information sources is inconsistent, we consider data discovered via the more trustworthy source as correct. For example, the distribution list provided by Infogroup didn’t include LocalStack.com as part of Infogroup’s distribution network. However, the results of both the Data Aggregators Study and the Citation Audit Study suggested that LocalStack does receive business data from Infogroup. Thus, an Infogroup —> LocalStack relationship was added as a “confirmed relationship” in the LSE infographic.
An opposite example would be a relationship between MapQuest and Localeze that was reported in Localeze’s distribution list. However, this relationship was not confirmed by any of our empirical studies, nor by MapQuest’s Director of Local Data and Partner Management Andy McMahon. As such a Localeze —> MapQuest relationship was added as “unconfirmed relationship” in the LSE infographic.
This way of ranking business data information relationships made it easier to analyze the results and prepare the final infographic. In some cases, however, even this way of simplifying things was insufficient to understand more complicated cases. For example, during our Data Aggregators Study we stumbled upon a very interesting discovery – business data we “seeded” on Acxiom in our data aggregator study eventually appeared on Localeze. When analyzing the data two different hypotheses emerged:
Hypothesis A: There is no direct relationship between Acxiom and Localeze. Some other site in Acxiom’s network got the data and generated a listing. Then Localeze “scraped” the data from that site and created their own listing. The fact that we also discovered an existing listing with the same data on Yellowpages, and knowing the overall prominence of Yellowpages in the local search ecosystem, the most likely site from which Localeze might have taken the data appeared to be Yellowpages. To summarize, the relationships in this case would look like this:
- Acxiom –> Yellowpages
- Yellowpages –> Localeze
Hypothesis B: Plain and simple – there may be a direct relationship between Acxiom and Localeze. However, there is no direct relationship between Acxiom and Yellowpages, and the Acxiom data came to Yellowpages via Localeze. In this case the relationships would look like this:
- Acxiom –> Localeze
- Localeze–> Yellowpages
While it is impossible to say for sure which of the two hypotheses is correct, we decided to go with B in the final version of the LSE. The main reason is because a relationship with Yellowpages is mentioned in Localeze’s distribution list, but such a relationship is not mentioned in Acxiom’s distribution list. Additionally, a relationship between Localeze and Yellowpages was confirmed via our Citation Audit Study. This made hypothesis B look like the more plausible scenario.
Excluded Data Sources
A large number of additional data sources and relationships were excluded from this version of the infographic. Such data sources could be grouped in the following manner:
1) Proprietary Data – some sites, such as the major data aggregators, Cylex, HotFrog, and TripAdvisor, generate listings based on business data they collect on their own. These sites use different methods of collecting such data, including directly calling the businesses, or using information found on business websites. Note that this is different from having business owners or representatives go to the sites and add new listings themselves (pretty much all major data aggregators and business directories allow for this).
2) Government Sources – many data aggregators and business directories use business data provided by public institutions to maintain their databases. Such data comes from many different government sources. Thus, having a combined “Government Sources” label in the LSE infographic wouldn’t be very helpful.
3) Less Significant Sources – there are literally hundreds of other data sources different sites use. I already linked a bunch of times to the Apple Maps attributions page, which is a very good example. Factual have a feature called Crosswalk, through which they collaborate with business directories (and other types of sites) and display links on their own listing pages to third-party pages for the same business. The full list of the sites Factual collaborate with is not publicly accessible, but their total number is more than 50.
Yellowpages is also rumoured to get business data from close to 50 sources, some of which are BBB and Groupon. Hopefully we will manage to find enough space for these currently excluded sources in future versions of the infographic.
Observations
Localeze’s Importance is Declining
One of the most important trends that have been observed during the last few years is the continuously diminishing importance of Localeze. Back in 2012 David noted that Localeze’s importance was on the rise. However, in 2017 it seems like a lot fewer sites are using Localeze data compared to before.
For instance, very little empirical evidence was found of Google, Facebook, MapQuest, Here, HotFrog, Kudzu, LocalStack, Manta, or MerchantCircle using Localeze business data. All of these sites were included in Localeze’s data distribution list, though. This could mean that they buy data from Localeze, but eventually do not use it. If that is the case, the most likely reason for this is the perceived inaccuracy or lower quality of Localeze’s data. It is generally difficult for businesses to keep their listings on Localeze correct. Back in 2013 Localeze stopped allowing free listing additions, which means that new businesses can only be added to Localeze after they pay. Additionally, a business that has an existing listing on Localeze could only update their basic business details (business name, address, main phone number, 1 category) once per year for free. If that business might want to add richer information – website, more categories, relevant keywords, additional phone numbers, payment methods accepted – or if they would like to update their business details more than once per year, they would need to pay a pretty hefty retail fee.
It Is Becoming Impossible to Update or Add a Listing on Factual
Worrisome issues have also been observed in the last couple of years with Factual. While it is undoubtedly an important data aggregator, and could be considered part of the “Big Four”, many businesses and agencies find it close to impossible to add, or worse, update their business information on Factual. The turnaround times for updates on Factual have always been long, starting from about a week in 2013, to 2-3 months in 2014-2015. Nowadays it seems like it is pretty much impossible to get a Factual listing updated, no matter the method you use. You can try to send the updates via their API, or manually, but all of these methods seem to rarely work, and it is unclear if in those instances where changes occur they are prompted by the submitted reports. If this issue is not rectified, Factual’s data quality will continue to decline, and it may lose its influence as a data aggregator.
**(Since publishing this study Factual has joined forces with Foursquare in early 2020)
There’s a Secondary Group of Key Sites That Could Be Considered Semi-Data Aggregators
Some “key sites” in the current version of the LSE seem to be as important data sources as the Big Four data aggregators. Yelp feeds review (and business) data to Bing, Apple Maps, Yellowpages, Yahoo! Local, and MapQuest. Yellowpages feeds Yelp (the deal is reciprocal), Yahoo! Local (there used to be an attribution page on Yahoo! Local), MapQuest, and a large number of smaller sites. Both Apple Maps and Bing use Foursquare data. The CityGrid network claims to include Google, Bing, Citysearch, Insiderpages, MapQuest, EZLocal, and a number of other niche sites. Overall, Yelp, Yellowpages, Foursquare, and CityGrid could be viewed as the “Dirty Four” – a secondary group of 4 semi-data-aggregators that are not as well-known as the Big Four, but that are almost as important when it comes to making sure a business’s data is accurate (and stays accurate) across the web. Ignore these at your own risk.
Conclusion
While we used a number of new methods to figure out existing business data relationships, some of our research results were inconclusive. Thus, in the next version of the LSE, we will include data from additional research that is currently underway at Whitespark.
Given the dynamic nature of these relationships, a future version of the LSE could look very different than what we are seeing now. A number of sites appear to be moving towards a model where they pull data only one time from a data aggregator’s feed, and then they use their in-house capabilities to keep the data up to date – including by setting up their own crawlers (HotFrog), sourcing data directly from the business’s website (Cylex), or communicating with each business on a regular basis (TripAdvisor). This means that “Proprietary Data” could become an important part of the next version of the infographic.
And for all of you wondering about other countries, we will be releasing local search ecosystems for Canada, the UK, Australia, Germany, and Brazil in the coming months.
Finally, thank you, David, for your work defining the local search ecosystem and establishing it as one of the most important resources in our industry, and for your input and collaboration to produce this latest version.